

服务介绍
DNA测序是指对DNA分子的核苷酸序列进行分析和测定的过程。DNA测序技术已经广泛应用于基因组学、生物学、医学、农业、环境科学等领域,为研究人员提供了研究生物体结构和功能的重要手段。目前,第一代DNA测序技术的出现,使得测序速度和准确度得到了大幅提升,有望进一步推动生命科学领域的研究和发展。
服务优势
- 速度更快:PCR产物和质粒24h内发送测序结果,菌液样本48h内发送测序结果;
- 测序更专业:正常样品有效测序长度可达800bp,测难度序列成功率高,品质有保障;
- 服务更贴心:武汉三镇驻点,随时上门取样,24h售前售后服务,及时解决您的任何问题;
- 活动更丰富:不间断推出各种惊喜活动,详情请咨询区域销售经理。
服务流程
客户提供
测序信息单,测序样品(包括菌液、质粒、PCR产物)和测序引物。

最终交付
- 测序结果,包括1份ab1格式的图谱文件和1份seq格式的序列文件
服务说明
|
服务内容 |
细分 | 服务周期 |
| 菌液测序/质粒测序/ PCR产物测序 |
<10反应 |
1-2工作日 |
|
≥10反应 |
1-2工作日 | |
|
≥100反应 |
2-3工作日 | |
|
大规模测序 |
2-3工作日 | |
| 设计合成测序引物 | 合成量2OD,PAGE 纯化 | 1-2工作日 |
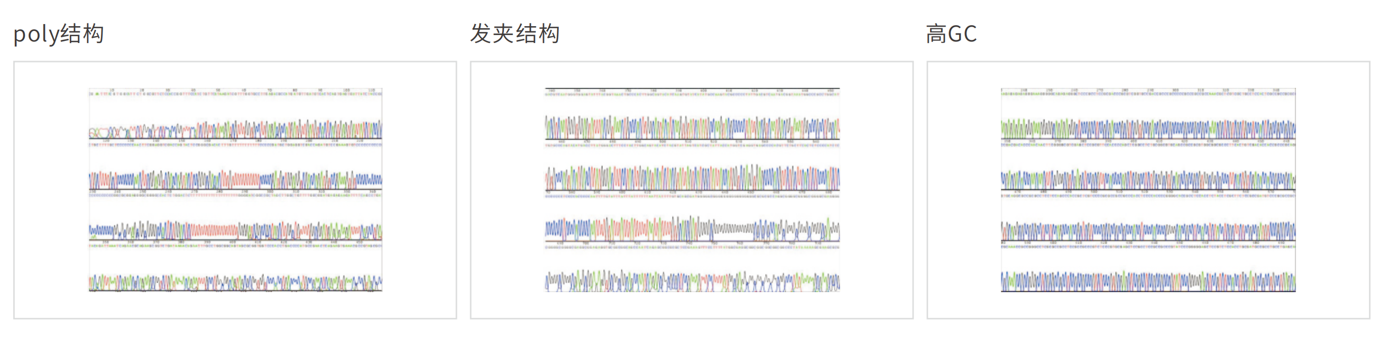
案例展示

常见问题与解析 (Q&A)
溶解DNA测序样品时,用灭菌蒸馏水溶解最好。DNA的测序反应也是Taq酶的聚合反应,需要一个最佳的酶反应条件。如果DNA用缓冲液溶解后,在进行测序反应时,DNA溶液中的缓冲液组份会影响测序反应的体系条件,造成Taq酶的聚合性能下降。 有很多客户在溶解DNA测序样品时使用TE Buffer。的确,TE Buffer能增加DNA样品保存期间的稳定性,并且TE Buffer对DNA测序反应的影响也较小,但根据我们的经验,我们还是推荐使用灭菌蒸馏水来溶解DNA测序样品。
我们推荐客户提供菌体,由我们来提取质粒,这样DNA样品比较稳定。如果您可以提供DNA样品,我们也很欢迎,但一定要注意样品纯度和数量。如果提供的DNA量不够,我们就需要对质粒进行转化,此时需收取转化费。有些质粒提取法提取的DNA质量很好,象TaKaRa、Qiagen、Promega的质粒制备试剂盒等。 提供的测序样品为PCR产物时,特别需要注意DNA的纯度和数量。PCR产物必须进行切胶回收,否则无法得到良好的测序效果。 有关DNA测序样品的详细情况请严格参照"测序样品的提供"部分的说明。
如果DNA片段在载体上,可以用载体上两端的引物同时测序,让其中间交叉互补,便可完全测通。如果这样还读不通,可根据已经测出的序列设计测序引物作进一步测序(此称为Primer Walking法),便可完全测通。
相关资源
1、高通量测序技术如新一代测序(Next-Generation Sequencing, NGS)已经日趋成熟,Sanger测序(一代测序)为什么没有被完全取代?
Sanger测序的准确性和可靠性使其成为这些特定应用领域的首选方法之一。尽管在大规模基因组测序中已经被新一代测序技术取代,但Sanger测序在需要高度准确性和可靠性的实验中仍然发挥着重要作用。例如:
● 基因克隆:Sanger测序常用于基因克隆中的序列验证。在构建基因工程载体或插入DNA片段时,需要确认目标序列的正确性和准确性。
● 突变检测:Sanger测序可以用于检测DNA序列中的点突变、插入缺失或重排等突变。它在研究遗传性疾病、癌症突变分析和个体基因组分析中具有重要作用。
● Sanger验证:在新一代测序(NGS)等高通量测序技术中,由于其可能存在的错误率,Sanger测序通常被用作验证方法。通过对特定区域进行Sanger测序,可以确认高通量测序结果的准确性。
2、Sanger测序(链终止法测序)和新一代测序技术对比介绍
| 分类 |
Sanger测序 |
新一代测序技术 |
| 原理 |
链终止法测序,通过合成链终止的核苷酸来确定DNA序列 |
并行测序原理,同时测序数百万至数十亿个片段 |
| 工作流程 |
DNA模板制备、引物设计、PCR扩增、测序、电泳分离、数据分析 |
DNA样本制备、文库构建、测序、数据分析 |
| 读长 |
较长(通常800-1,000个碱基对),适用于较小的DNA片段 |
较短(通常数十到数百个碱基对),适用于整个基因组的测序 |
| 产出 |
相对较低,单个测序仪器产出数百到数千个片段 |
高,单次测序可产出数百万至数十亿个片段 |
| 成本 |
相对较高,包括设备、试剂和人力成本 |
相对较低,高通量平台降低了测序成本 |
| 应用 |
适用于特定应用,如基因克隆、突变检测、Sanger验证等 |
适用于全基因组测序、转录组测序、表观遗传学等广泛应用 |
| 优势 |
可以得到较长的读长,序列质量较高 |
高通量、高效率、适用于大规模测序和多样本分析 |
| 局限性 |
产出量相对较低,不适用于大规模测序项目 |
读长较短,可能存在测序错误和序列重叠的问题 |








